Building Scalable Data Lake Using AWS

Data lakes are centralized repositories that facilitate flexible and economical data management, and businesses are using them to store, process, and analyze this data effectively. AWS offers a strong ecosystem for creating a safe and scalable data lake with services like Lake Formation AWS Glue and Amazon S3.
Along with best practices for implementation, this article examines the essential elements of an AWS Data Lake architecture, including ingestion storage processing and analytics.
Architectural Layers
Data Ingestion Layer
Sources of Data
Data can originate from various sources, such as logs, databases, IoT devices, social media feeds, and more.
Ingestion Tools and Services
- AWS Kinesis Data Streams/Firehose: For real-time streaming ingestion.
- AWS Data Migration Service (DMS): For migrating relational databases.
- AWS IoT Core: For ingesting sensor/IoT data.
- Custom APIs or Lambda functions: For processing incoming data in real time.
Storage Layer
Primary Storage
- Amazon S3: Acts as the central repository (data lake) with a multi-tier storage model (raw, processed, curated).
- S3 buckets organization:
- Raw zone: Holds the unprocessed, original data.
- Cleansed/processed zone: Contains data after transformation and cleaning.
- Curated zone: Data that is refined and ready for analytics or consumption by business users.
Cost Management and Lifecycle Policies
Use S3 Lifecycle policies to move older data to lower-cost storage classes (e.g., S3 Glacier).
Metadata and Cataloging
Metadata cataloging improves searchability and enables efficient schema discovery when using query services like Athena.
- AWS Glue Data Catalog: Automatically discovers, catalogs, and organizes data across S3.
- AWS Lake Formation: Simplifies setting up, securing, and managing the data lake. It also handles fine-grained access control and auditing.
Data Processing and Transformation Layer
ETL (Extract, Transform, Load) Services
- AWS Glue: Serverless ETL service to clean, enrich, and transform raw data.
- Amazon EMR: For big data processing using Apache Spark, Hive, or Presto if more custom or resource-intensive transformations are needed.
Serverless Compute
-
AWS Lambda: For lightweight, event-driven transformations as new data arrives.
Data Analytics and Query Layer
Business users query processed data using Athena for ad hoc reporting, while periodic batch reports can be scheduled in Redshift.
Interactive Query Tools
- Amazon Athena: Enables SQL-based querying directly on data in S3 without the need to provision servers.
- Amazon Redshift Spectrum: Allows you to query data in S3 with your data warehouse.
Business Intelligence (BI) and Visualization
- Amazon QuickSight: For dashboards and visualizations that provide insights into data trends and performance.
- Third-party BI tools: Can be integrated via connectors.
Security, Governance, and Monitoring
Access Control and Data Protection
- AWS IAM: To manage user access and roles across all services.
- AWS Lake Formation: Provides fine-grained access controls, auditing, and data encryption.
- Encryption: Both in transit (using SSL/TLS) and at rest (using S3 server-side encryption or client-side encryption).
Monitoring and Logging
- Amazon CloudWatch: To monitor performance metrics and set alarms.
- AWS CloudTrail: For logging API calls and ensuring compliance.
- AWS Config: To continuously monitor and record AWS resource configurations for governance and auditing.
Architecture
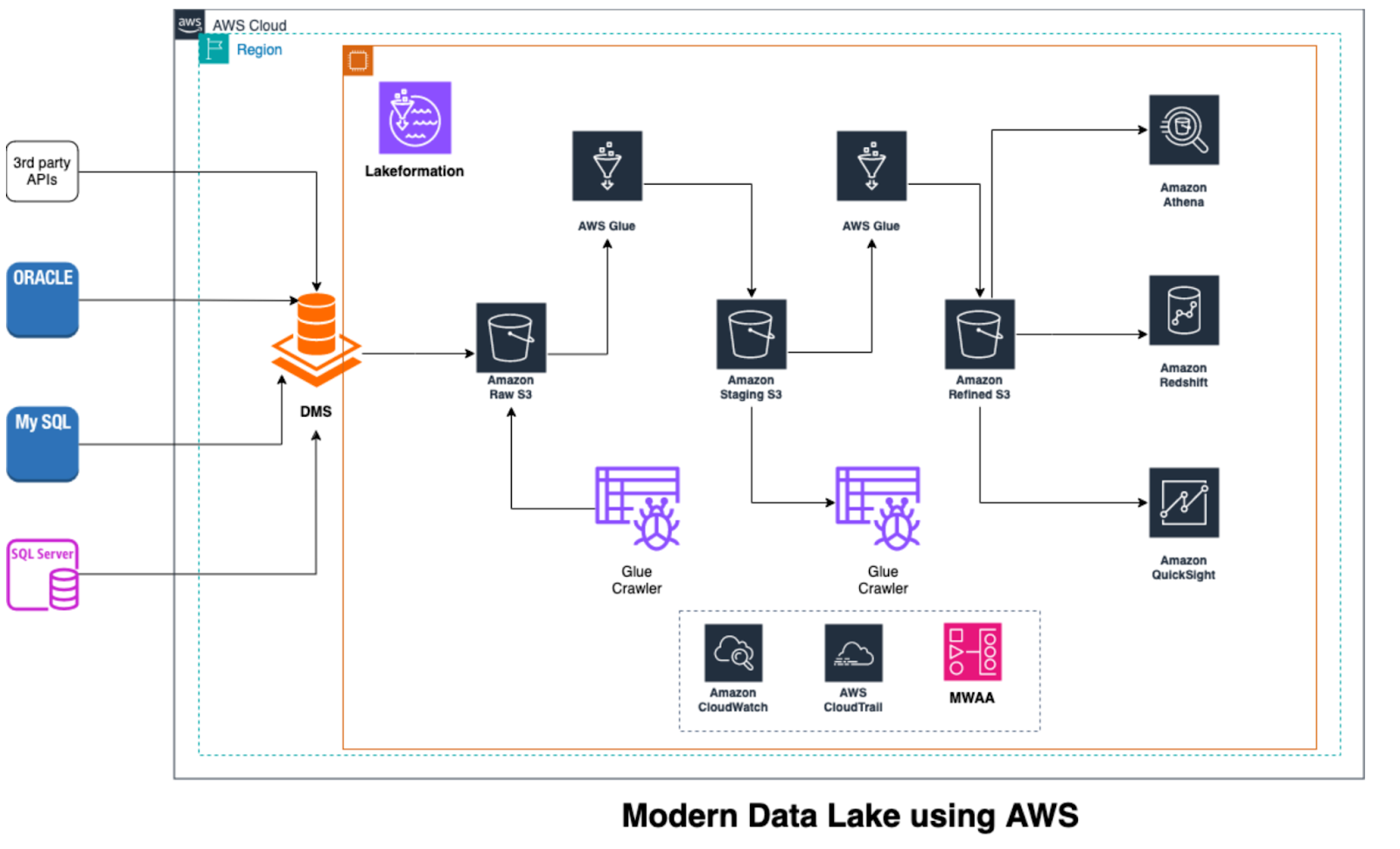
Source data in this architecture may come from third-party APIs or databases like Oracle MySQL and SQL Server. Data Migration Service (DMS) is an ingestion mechanism offered by AWS that can establish a connection with a database, read data continuously, and write it to an Amazon S3 bucket. Additionally, DMS provides Change Data Capture (CDC) capabilities, which enable it to stream changes straight into the raw S3 bucket and read database logs.
An Amazon Glue Crawler is set up to scan the data and produce a matching table in the AWS Glue Data Catalog as soon as the data is accessible in the raw S3 bucket. An AWS Glue ETL job then processes this raw data, making the required changes and writing the results to a staging S3 bucket.
For the staging layer, a similar procedure is used: a second Glue crawler updates the data catalog so that later AWS Glue ETL jobs can read the transformed data. These jobs store the final output in a refined S3 bucket after further refining the data. Currently, Amazon Athena or Redshift Spectrum can be used to run analytical queries, and Amazon QuickSight can help with reporting and visualization. AWS Step Functions or Managed Workflows for Apache Airflow (MWAA) can be used to orchestrate the entire data pipeline.
Access controls are managed for all raw, staging, and refined S3 buckets using AWS Lake Formation for data governance and security. Furthermore, AWS CloudTrail and Amazon CloudWatch thoroughly monitor and audit the data lake environment.
Additional Considerations
- Scalability: AWS services like S3, Glue, and Kinesis are designed to scale with your data volume.
- Cost optimization: Use tiered storage and serverless options (Glue, Lambda) to control costs, and leverage reserved capacity if predictable workloads exist.
- Data quality and lineage: Incorporate mechanisms in your ETL jobs to capture data lineage and ensure quality controls, potentially using AWS Glue’s built-in features or third-party solutions.
- Integration with machine learning: Once data is curated, integrate it with Amazon SageMaker for predictive analytics and advanced data insights.
Conclusion
From ingestion to consumption, this AWS Data Lake architecture provides a reliable, adaptable, and safe method of managing data. In addition to offering the fundamental features required for data processing and storage, the architecture guarantees that data is readily discoverable, governed, and prepared for analytics by combining a wide range of AWS services.
